
はじめに
Pandas基礎①に続いて、Pythonのデータ分析において必須のライブラリである、Pandasについてまとめます。
データの選択と抽出
DataFrameの作成
df.loc
df.loc['A']
# output
'''
C1 1.764052
C2 0.400157
C3 0.978738
C4 2.240893
C5 1.867558
Name: A, dtype: float64
'''df.loc['A', ['C1', 'C3']]
# output
'''
C1 1.764052
C3 0.978738
Name: A, dtype: float64
'''df.iloc
df.iloc[2, 3]
# 0.121675スライス(:)で複数行・複数列を指定できます。
df.iloc[:3, 1]
’’’
A 0.400157
B 0.950088
C 1.454274
Name: C2, dtype: float64
’’’条件による選択
df[df > 0]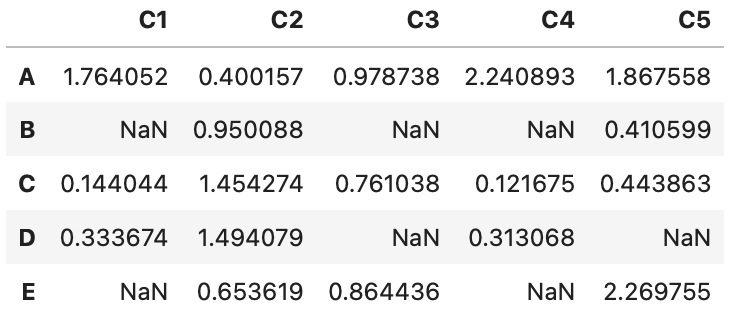
df[df['C1'] > 0]
df[(df['C1'] > 0) & (df['C1'] < 1)]
データの追加と削除
データの追加
df['new_column'] = df['C1'] * df['C2']
df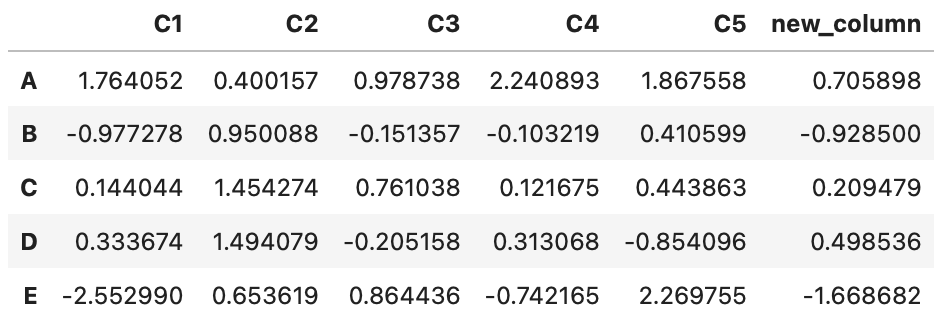
データの削除
データの削除に使用するdropメソッドは、行名・列名をそれぞれ指定することが出来ます。inplace引数をTrueにすると、元のdfが更新されます。
# この場合は更新されない
df.drop(columns=['C1'])
df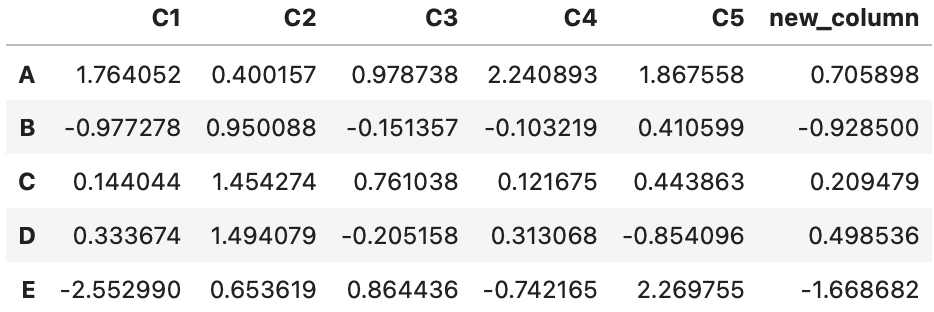
# DataFrameが更新される
df.drop(columns=['C1'], inplace=True)
df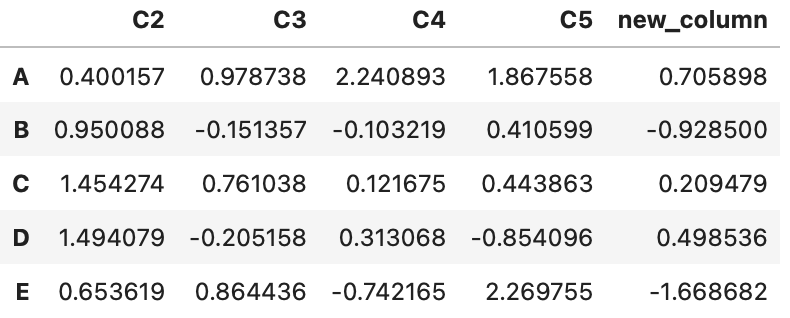
欠損値の処理
欠損値nan(not a number)を処理する場合は、次のメソッドが便利です。
df = pd.DataFrame(data=[[1, 2, 3, np.nan, 4],
[5, np.nan, 6, np.nan, 7],
[8, 9, 10, np.nan, 11],
[12, np.nan, np.nan, np.nan, 13],
[14, 15, 16, 17, 18]],
index=['A', 'B', 'C', 'D', 'E'],
columns=['C1', 'C2', 'C3', 'C4', 'C5'])
df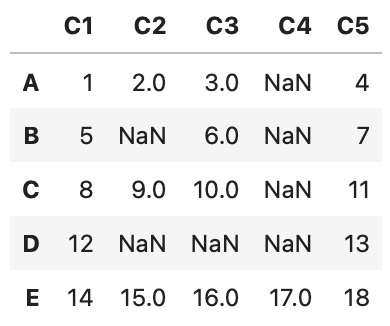
df.dropna
欠損しているデータを削除
df.dropna()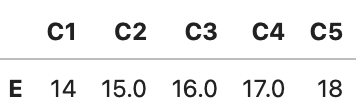
特定の列の欠損値がある部分を削除
df[df['C2'].isnull() == False]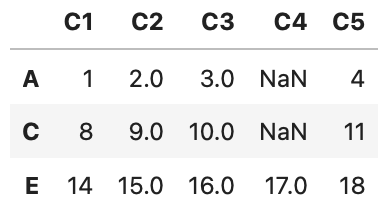
欠損値の数を指定して削除
df.dropna(thresh=3)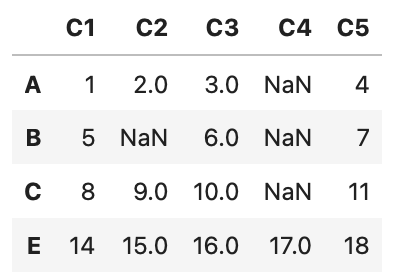
列の削除
df.dropna(thresh=3, axis=1)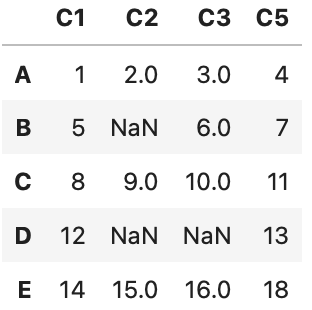
df.fillna
欠損値を別の値で埋めます。次の場合は平均値に置換しています。
df['C2'].fillna(df['C2'].mean())
df.fillna(df.mean())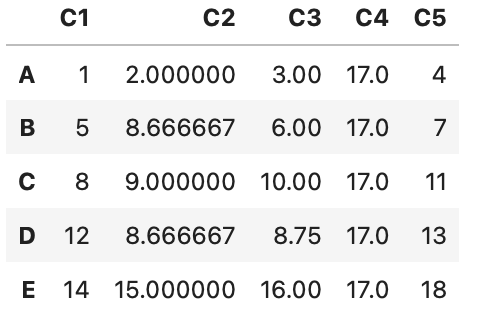
引き続き、Pandasについてまとめていきます。