
はじめに
Numpy基礎に続いて、Pythonのデータ分析に必須となるPandasについてまとめます。
Pandasはエクセルのような表形式のデータを簡単に取り扱うことの出来る、非常に優れたライブラリです。
SeriesとDataFrame
Pandasには、Seriesと呼ばれる1次元のデータ構造を持つクラスと、DataFrameと呼ばれる2次元のデータ構造を持つクラスが存在します。下図のように、Seriesを組み合わせた物がDataFrameです。いずれも重要なデータ構造なので、それぞれの基本的な操作をについて記載します。
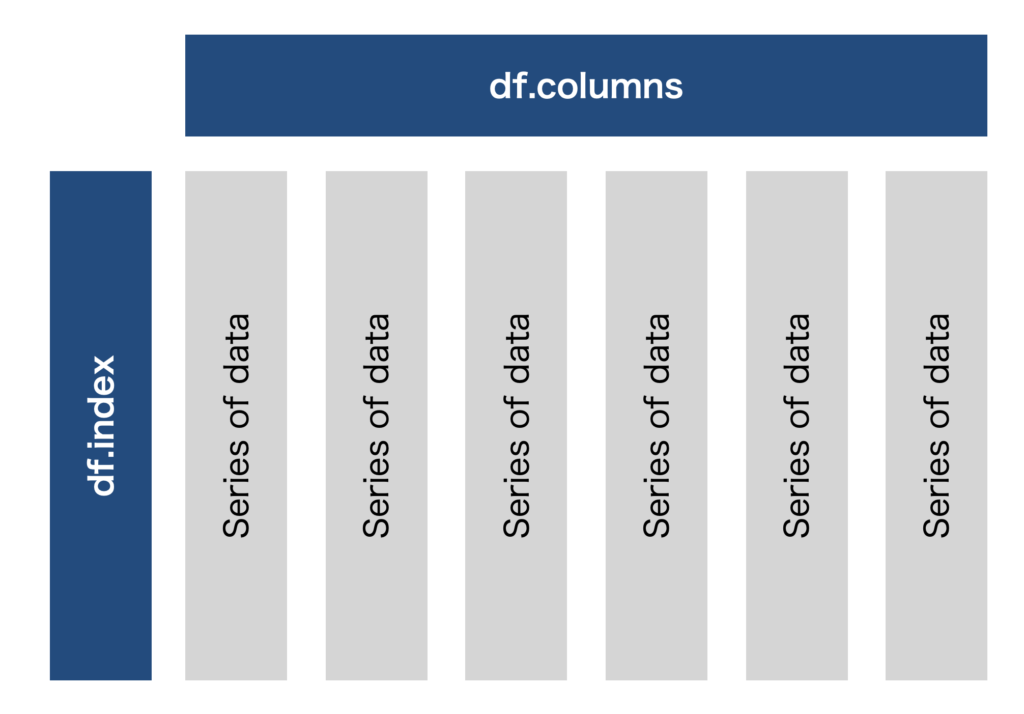
Pandasのインポート
import pandas as pdSeriesクラス
pd.Series
Seriesを生成できます。
series = pd.Series(data = [1, 2, 3, 4, 5], index = ['A', 'B', 'C', 'D', 'E'])
series
# A 1
# B 2
# C 3
# D 4
# E 5
# dtype: int64numpyの配列やリストを指定できます。
array = np.arange(1, 11)
index = 'a b c d e f g h i j'.split()
series = pd.Series(data = array, index = index)
series
# a 1
# b 2
# c 3
# d 4
# e 5
# f 6
# g 7
# h 8
# i 9
# j 10
# dtype: int64データの選択
直接indexを指定してデータを取り出すことも可能ですが、多くの場合はlocメソッドやilocメソッドを使用します。
locメソッドではindex名を、ilocメソッドではデータのindex番号を指定します。
series = pd.Series(data = [1, 2, 3, 4, 5], index = ['A', 'B', 'C', 'D', 'E'])
series['E']
# 5
series['A':'D']
# A 1
# B 2
# C 3
# D 4
# dtype: int64
series.loc
series.loc['A']
# 1series.loc[['B', 'D']]
# B 2
# D 4
# dtype: int64series.iloc
series.iloc[0]
# 1series.iloc[:3]
# A 1
# B 2
# C 3
# dtype: int64DataFrameクラス
pd.DataFrame
Data Frameを生成できます。
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
df = pd.DataFrame(data)
df.columns = ['A', 'B', 'C']
df.index = ['a', 'b', 'c']
df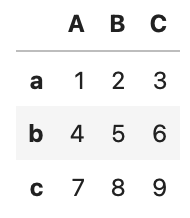
df.head()
df.head()メソッドで、先頭の5行を表示できます。
from sklearn.datasets import load_iris
iris = load_iris()
iris_df = pd.DataFrame(data = iris.data, columns = iris.feature_names)
iris_df.head()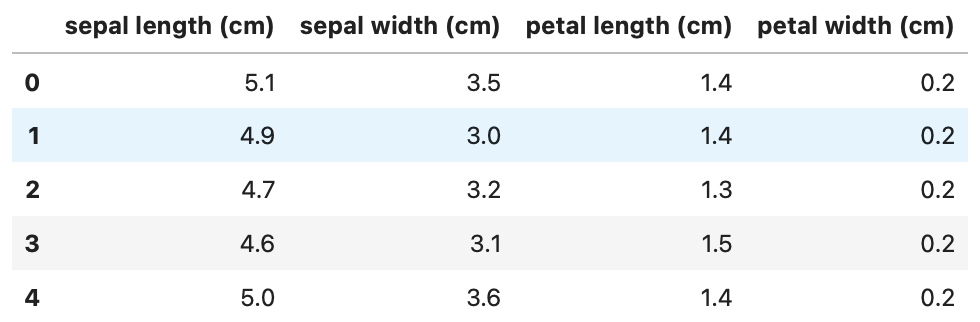
df.tail()
df.tail()メソッドで、末尾の5行を表示できます。
pd.read_csv
pandasを使えば、csvやexcel、HTMLなど様々なファイルを読み込むことが可能です。
df = pd.read_csv('train.csv')
df.head()
csvに日本語が含まれている理由などでエラーが出る場合は、文字コードを指定します。headerの数字を指定することで、csvファイルの読み込みを開始する行を指定することが出来ます。
df = pd.read_csv('---.csv', header = 100, encoding = 'shift-jis')データの概要把握
df.shape
DataFrameの形状を確認できます。
df.shape
# (891, 12)df.describe()
DataFrameの各種統計量を確認することが可能です。
df.describe()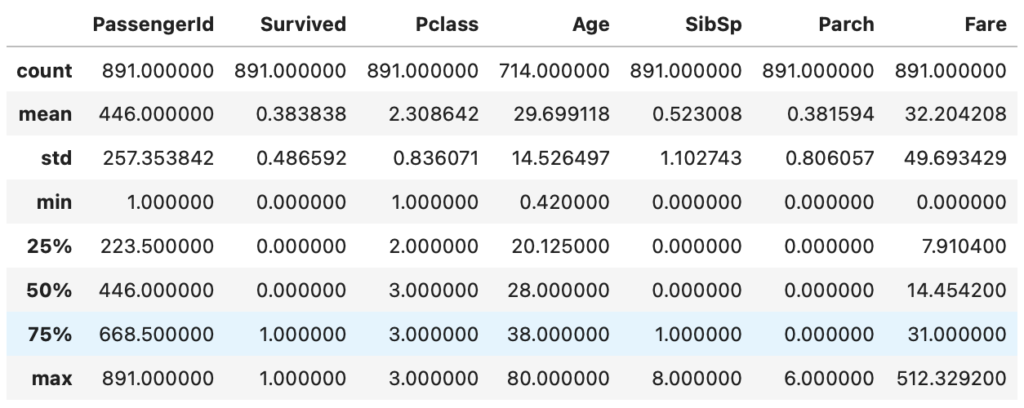
df.info()
各データ型とnullではない数を確認できます。
df.info()
’’’
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
'''df.nunique()
ユニークな値の数を確認することができます。
df.nunique()
’’’
PassengerId 891
Survived 2
Pclass 3
Name 891
Sex 2
Age 88
SibSp 7
Parch 7
Ticket 681
Fare 248
Cabin 147
Embarked 3
dtype: int64
’’’df.isnull()
欠損値の数を確認できます。
df.isnull().sum()
’’’
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
’’’df.index (行名)
df.index
# RangeIndex(start=0, stop=891, step=1)df.columns (列名)
df.columns
# Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
# 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
# dtype='object')続きは次回の投稿に記載します。