
概要
本記事では、k-最近傍法(k-NearestNeighbors)について解説します。
k最近傍法とは
k最近傍法は教師あり学習における、最もシンプルなアルゴリズムです。
import mglearn
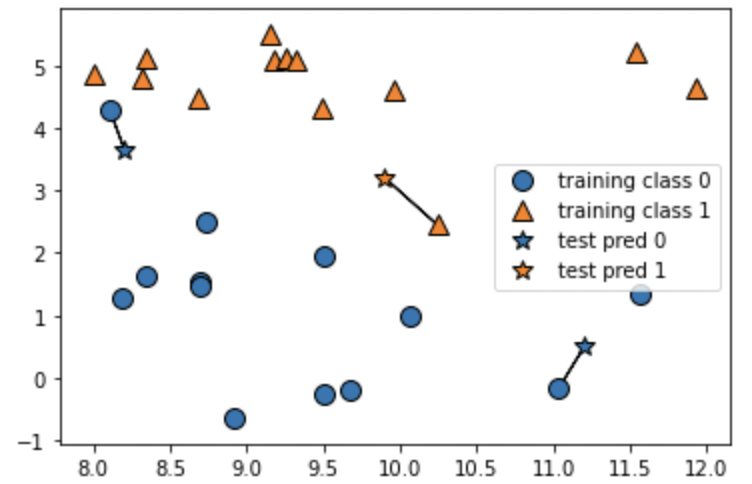
mglearn.plots.plot_knn_classification(n_neighbors=1)mglearnで簡単なk-NNの例を確認することができます。
2つの特徴量をX軸・Y軸として、0(オレンジ)と1(青)の2つのクラスがプロットされています。引数n_neighborsに1を渡した場合は、k-NNは訓練データセットの中で予測したいデータに最も近い1点だけを見て、この点のクラスを出力として吐き出します。下の画像では、星の3点のテストデータに対して、それぞれ訓練データで最も近い点に向かって線が引かれています。
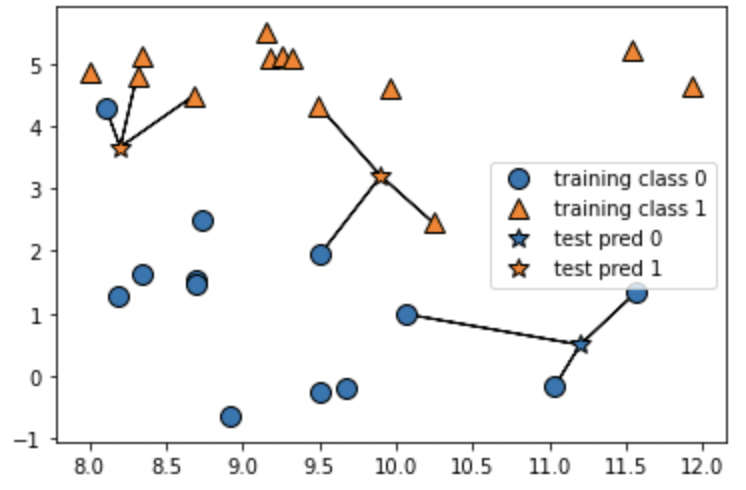
mglearn.plots.plot_knn_classification(n_neighbors=3)引数n_neighborsに3を渡した以下の例では、テストデータに近い3点の訓練データの中で、最も数が多いクラスを採用しています。
KNeighborsClassifiers
scikit-learnによる実装
KNeighborsClassifierクラスのインポート・インスタンス化は、下記のコードで行います。
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3)続いて、mglearnのforgeデータセット(人為的に作られたサンプルデータ)を用いて、scikit-learnでk-NNを試します。
# forgeデータセットの読み込み
X, y = mglearn.datasets.make_forge()
import matplotlib.pyplot as plt
# KNeighborsClassifierのインポート
from sklearn.neighbors import KNeighborsClassifier
fig, axes = plt.subplots(1, 3, figsize = (10, 3))
for n_neighbors, ax in zip([1, 3, 10], axes):
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=True, ax = ax, alpha = 0.5)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax = ax)
ax.set_title(str(n_neighbors) + " neighbor(s)")
ax.set_xlabel("feature 0")
ax.set_ylabel("feature 1")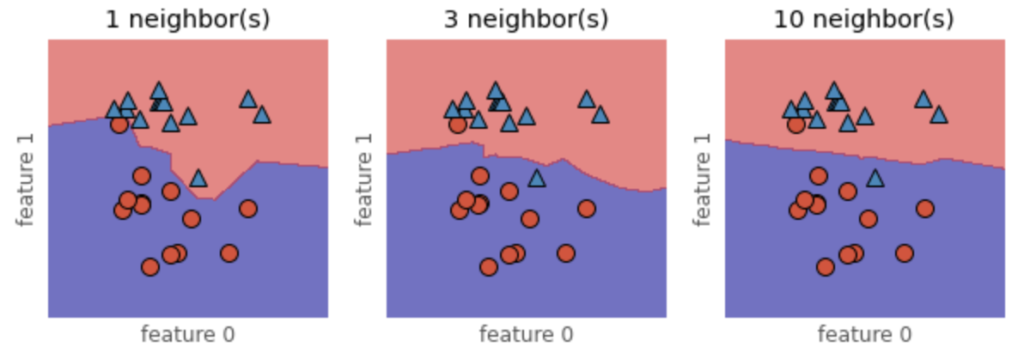
これにより2つのクラスの分類を決める決定境界が可視化できます。上の図の通り、1つの最近傍点を用いると、決定境界が複雑な線を描き、多くの最近傍点を考慮するとより滑らかな線になっており、より単純なモデルとなっていることが分かります。
予測精度の解析
下記のコードを実行し、n_neighborsの値に応じた予測精度を確認します。
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, \
stratify = cancer.target, random_state = 0)
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1, 61, 2)
for n_neighbors in neighbors_settings:
clf = KNeighborsClassifier(n_neighbors = n_neighbors)
clf.fit(X_train, y_train)
training_accuracy.append(clf.score(X_train, y_train))
test_accuracy.append(clf.score(X_test, y_test))
plt.figure(figsize=(8,4))
plt.style.use('ggplot')
plt.plot(neighbors_settings, training_accuracy, marker = 'o', label = "training_accuracy")
plt.plot(neighbors_settings, test_accuracy, marker = '^', label = "test_accuracy")
plt.ylabel("Accuracy")
plt.xlabel("n_neighbors")
plt.xlim(0, 60)
plt.ylim(0.88, 1.02)
plt.legend()
plt.show()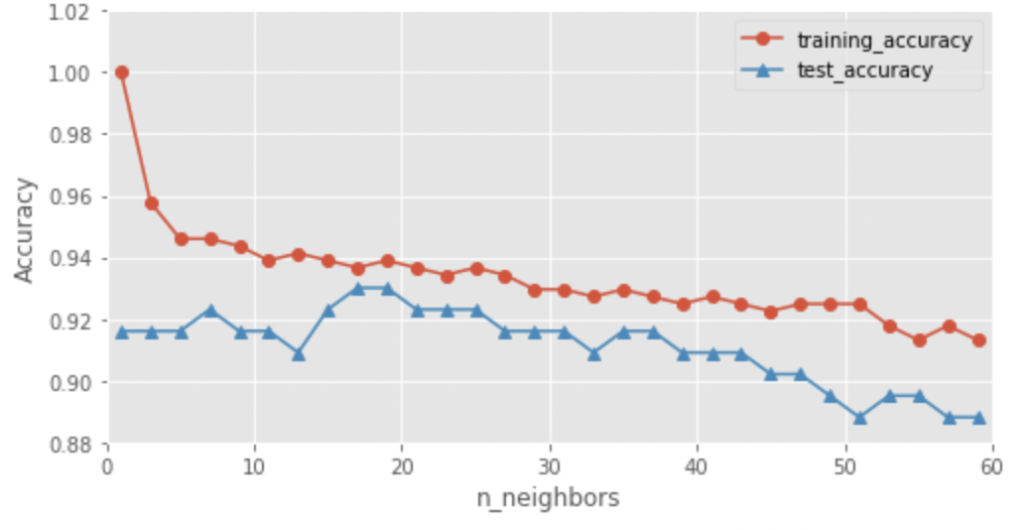
n_neighbors=1の場合には、訓練データに対しては100%予測できているが、多くの近傍点を考慮するほど、訓練データセットに対する予測は低下しています。これは、1つの近傍点のみを考慮する場合には、モデルが複雑化し過ぎることを意味します。一方で、テストデータに対する予測は、近傍点の数を増やすにつれて一旦上昇し、その後モデルが単純化し過ぎるために低下しています。最適な近傍点の数を設定することが重要であると分かります。
KNeighborsRegressor
mglearnによるサンプル
k-NNは回帰に使用することも可能です。mglearnによるk-NN回帰の例を確認します。
mglearn.plots.plot_knn_regression(n_neighbors=3)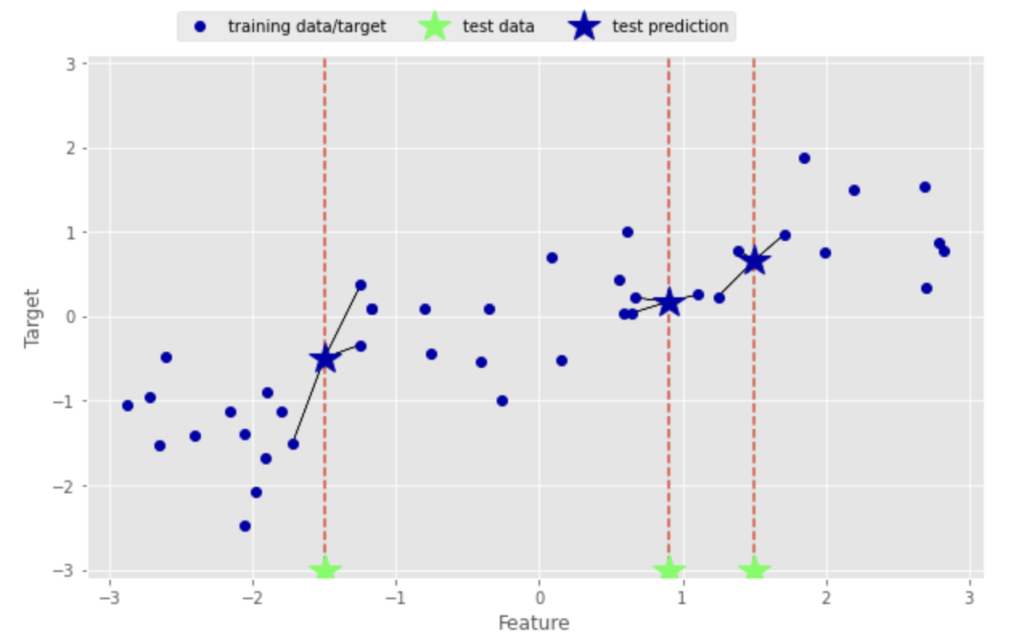
図から分かる通り、X軸のFeatureテストデータに対して、近傍点3点の平均値を予測値として算出をしています。
予測精度の解析
mglearnのwaveデータセットに対して、近傍点を1, 3, 9としてモデルを確認します。
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
X, y = mglearn.datasets.make_wave(n_samples=40)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
reg = KNeighborsRegressor(n_neighbors = 3)
reg.fit(X_train, y_train)
fig, axes = plt.subplots(1, 3, figsize = (18, 4))
line = np.linspace(-3, 3, 1000).reshape(-1, 1)
for n_neighbors, ax in zip([1, 3, 9], axes):
reg = KNeighborsRegressor(n_neighbors = n_neighbors)
reg.fit(X_train, y_train)
ax.plot(line, reg.predict(line), color = 'k')
ax.plot(X_train, y_train, '^', color = 'red', markersize = 8)
ax.plot(X_test, y_test, 'v', color = 'blue', markersize = 8)
ax.set_title("{} neighbor(s) \n train_score={:.2f}, test_score={:.2f}"\
.format(n_neighbors, reg.score(X_train, y_train), reg.score(X_test, y_test)))
ax.set_xlabel("Feature")
ax.set_ylabel("Target")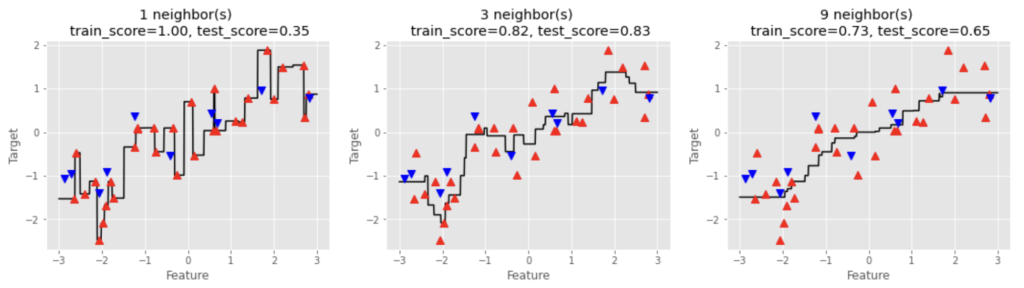
図より、n_neighbors=1の場合には、予測はすべての訓練データセットの点を通過しており、テストデータに対する予測精度が低いことが分かります。n_neighborsを上げていくと、モデルはよりシンプルになっています。訓練データに対する予測精度は徐々に低下していくのに対し、テストデータの予測精度は一度上がってから低下しています。
kNNのメリット・デメリット
メリット:理解しやすい
デメリット:
・特徴量やサンプル数が増えると処理速度が遅い
・疎なデータセット(ほとんどの特徴量が0の場合には性能が悪い)
といった特徴があります。