
はじめに
Pandasの基礎①、Pandasの基礎②に続き、Pythonのデータ分析において必須となるPandasについてまとめます。
内容については目次(CONTENTS)を参照ください。
カテゴリカルデータの操作
次のようなDataFrameに対して、操作を行います。
df = pd.DataFrame({'C1': ['A', 'A', 'A', 'B', 'B', 'C', np.nan],
'C2': [20, 50, 60, 80, 100, 30, 50],
'C3': [40, 200, 100, 500, 40, 200, 40]})
df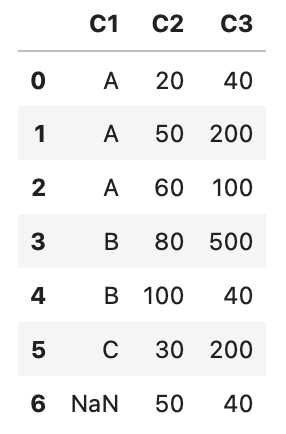
df.value_counts()
カテゴリとそれぞれのデータ数を確認
df['C1'].value_counts()
’’’
A 3
B 2
C 1
Name: C1, dtype: int64
’’’特定カテゴリのデータ抽出
df[df['C1'] == 'A']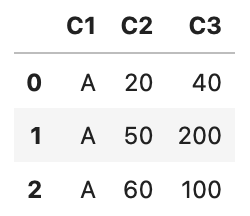
欠損値を最頻値で埋める
# df.mode()[0]:最頻値
df['C1'] = df['C1'].fillna(df['C1'].mode()[0])
df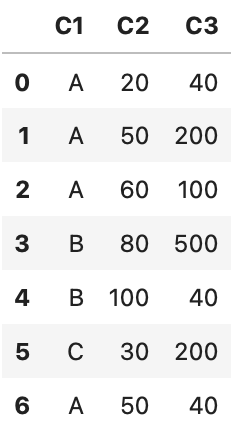
カテゴリの割合を算出
round(df['C1'].value_counts() / len(df), 2)
# A 0.57
# B 0.29
# C 0.14
# Name: C1, dtype: float64df.groupby
グループ化して各種統計量を計算することができます。
df.groupby('C1').sum()
df.groupby('C1').mean()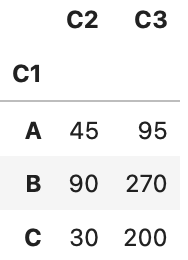
DataFrameの結合
pd.concat()
DataFrameを結合するメソッドにはさまざまなものがありますが、ここでは最も代表的でわかりやすいconcatメソッドを紹介します。
df_1 = pd.DataFrame(data=np.random.randn(5, 5), index=['A', 'B', 'C', 'D', 'E'],
columns=['C1', 'C2', 'C3', 'C4', 'C5'])
df_1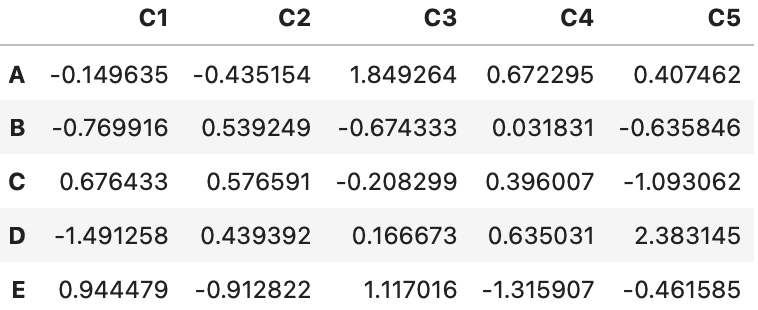
df_2 = pd.DataFrame(data=np.random.randn(5, 5), index=['F', 'G', 'H', 'I', 'J'],
columns=['C1', 'C2', 'C3', 'C4', 'C5'])
df_2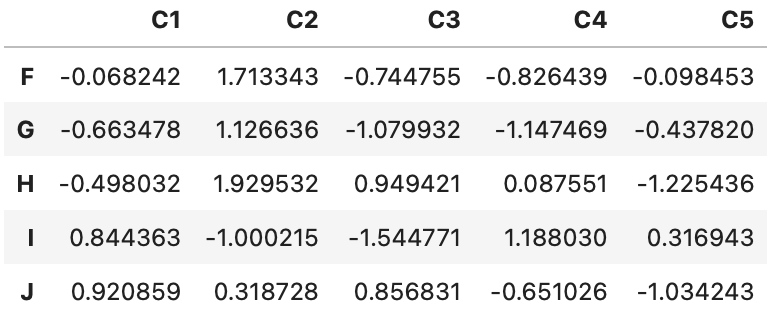
pd.concat([df_1, df_2])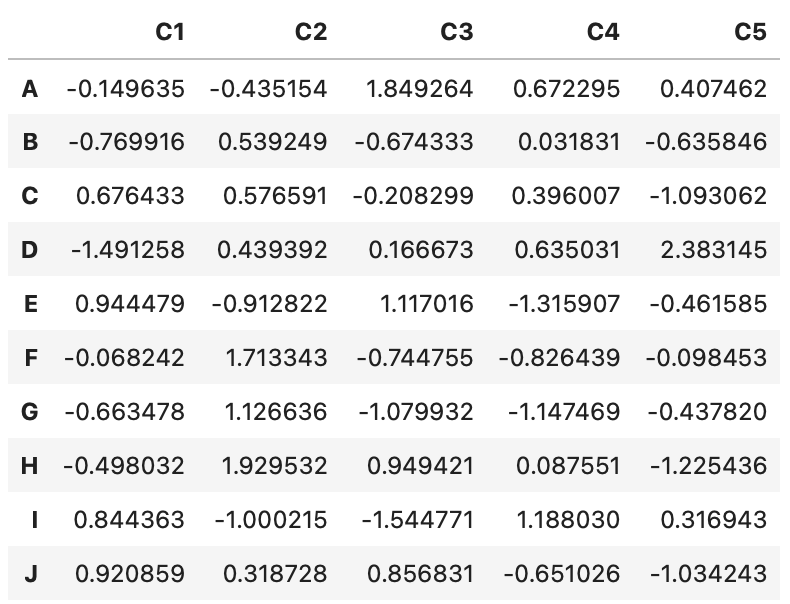
pd.concat([df_1, df_2], axis=1)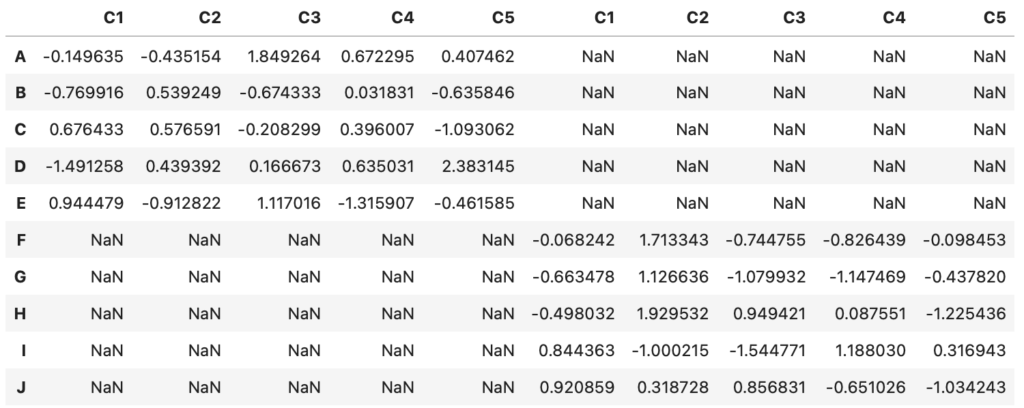
axisの引数がよく分からなくなった場合には、こちらの解説が参考になります。
他にも、DataFrameの結合に便利なmergeメソッドについては、こちらが参考になります。
関数の適用
df.apply()
DataFrameに対して関数を適用したい場合には、applyメソッドがあります。
df = pd.DataFrame(data=np.random.randint(0, 10, 25).reshape(5,5), index=['A', 'B', 'C', 'D', 'E'],
columns=['C1', 'C2', 'C3', 'C4', 'C5'])
df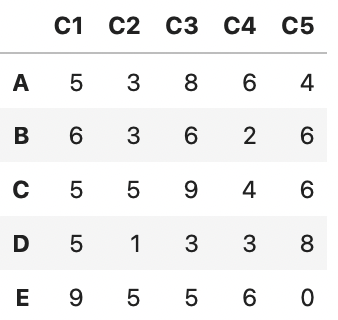
def square(x):
return x ** 2
df['C1'].apply(square)
'''
A 25
B 36
C 25
D 25
E 81
Name: C1, dtype: int64
'''複数の引数を取る場合
呼び出し時に特定のデータを指定する
def times(x, y):
return x * y
df['C1*C2'] = times(df['C1'], df['C2'])
df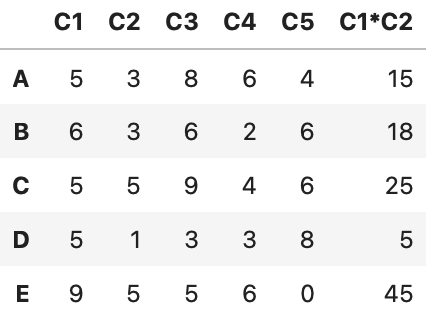
複数の返り値を取る場合
def square_root(x):
return pd.Series([x**2, x**(1/2)])
df[['squared', 'root']] = df['C1'].apply(square_root)
df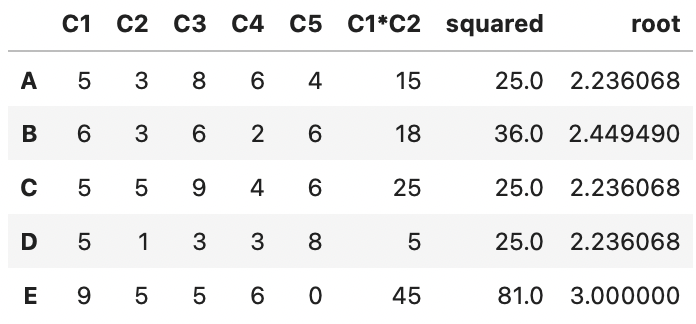
dfを引数に指定
def C1plusC2(df):
df['C1+C2'] = df['C1'] + df['C2']
return df
df.apply(C1plusC2, axis=1)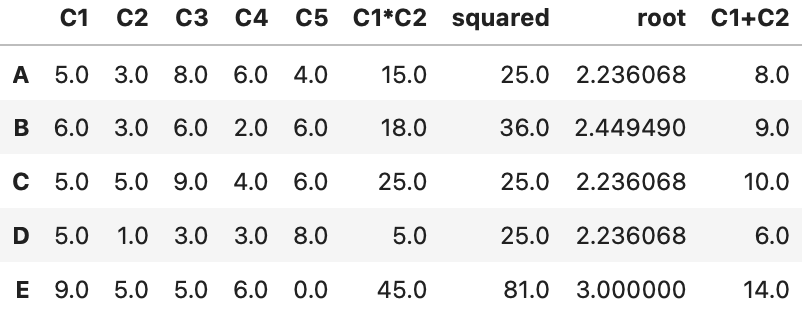
ファイルの吐き出し
csvファイルとして出力
df.to_csv("test.csv")Excelファイルの出力
df.to_excel('test.xlsx')シート名を指定したい場合は、下記のsheet_name引数にシート名を入力します。
with pd.ExcelWriter("test_2.xlsx") as writer:
df.to_excel(writer, sheet_name='dataframe')以上でPandasの基礎に関するまとめを終わります。