
はじめに
今回は、k最近傍法の解説に続いて、線形回帰の解説を行います。
線形回帰とは
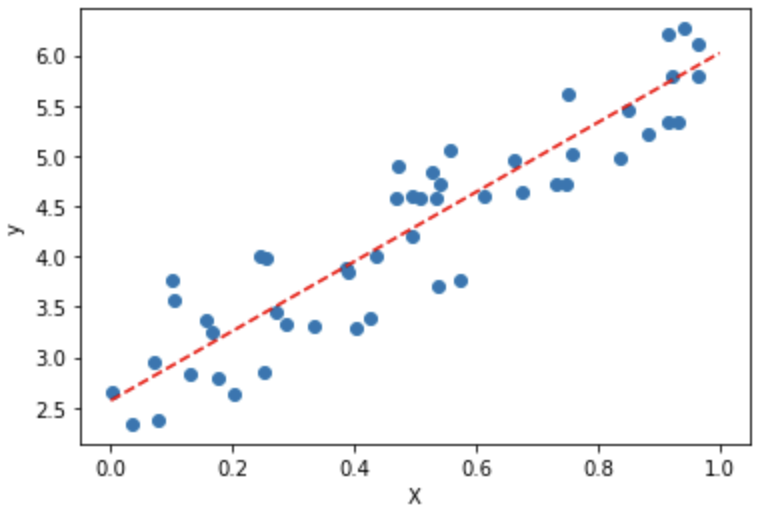
下図のように、あるデータの分布を線によって表現する手法のことを、線形回帰と呼びます。
特徴量が1つの場合の一般的な予測式は、 $$ y = AX + B $$
の形で記述することができます。つまり、ここでは最適なパラメータAとBを求める必要があります。
通常、このパラメータを算出するためには、最小二乗法を使用します。最小二乗法は、平均二乗誤差MSE(実際の値と予測値の差分の二乗を計算し、データ数で割った値)が最小になるようなパラメータを求める手法です。この平均二乗誤差を損失関数 Lとして定義すると、次の式で表されます。
$$ L=\frac{1}{n} \sum_{i=1}^{n}{(y_{i}-(ax_{i} + b))}$$
この損失関数Lの最小値を算出する際には、勾配降下法を用います。
勾配降下法の考え方
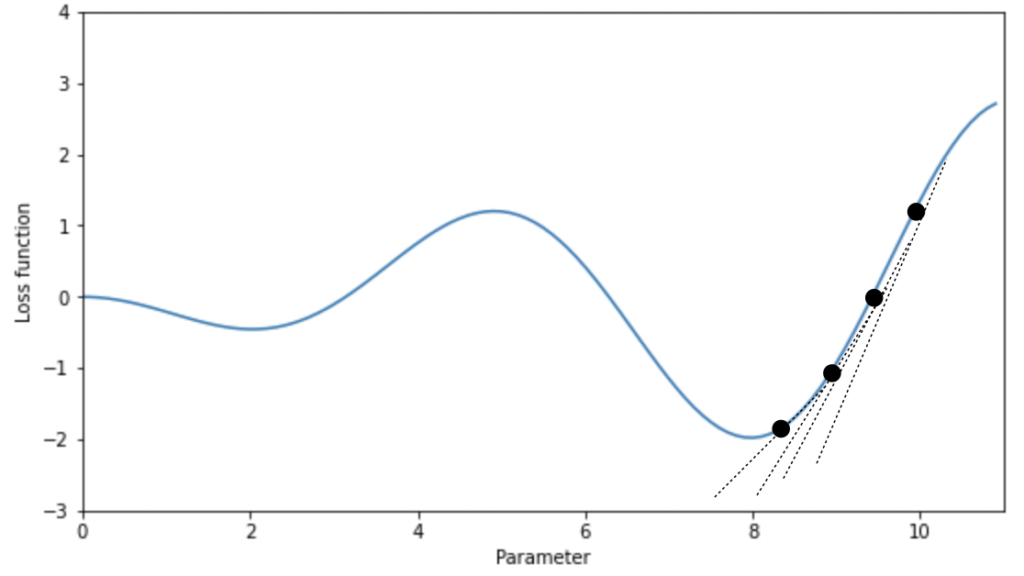
図のように、各パラメータに対してランダムに初期値を設定し、損失関数を計算します。続いて、パラメータによる偏微分を行い、設定した点における傾きを算出し、損失関数が小さくなる方向に対して、パタメータを調整します。上の図の場合には、右上の点から始まり、徐々に傾きが小さくなるように点を動かしていきます。この操作を繰り返すことによって、損失関数の傾きが0となる点を求めることで、損失関数を最小とする点を得ることができます。
このとき、パラメータの点を少しずつ左や右に動かすことを学習と呼び、どの程度の大きさでパラメータの更新を行うかを学習率と呼びます。この学習率が小さすぎると一向に最小値に到達しなかったり、大きすぎると最小値に収束しなかったりします。
Scikit-Learnによる実装
1次元データセットの予測
続いて、sklearnによる簡単な実装を試します。まず、numpyの乱数生成を用いて、適当なデータを生成します。
import numpy as np
X = np.random.rand(50, 1)
y = 2 + 3 * X + np.random.rand(50,1) * 1.5
plt.scatter(X, y)
plt.xlabel("X")
plt.ylabel("y")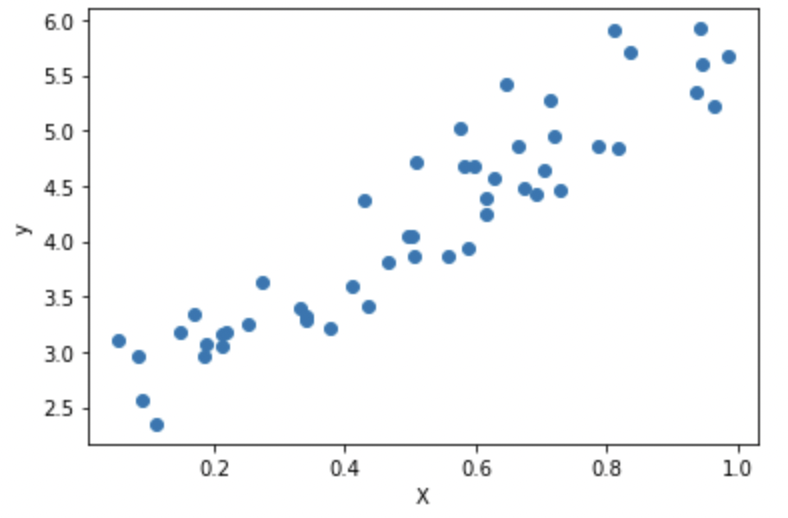
次に、sklearnのLinearRegressionクラスをインポートします。先ほどのデータを訓練データとテストデータに分割した後、fitメソッドを使用して学習を行います。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
lin_reg = LinearRegression().fit(X_train, y_train)これによって、訓練データに対するモデルを得ることができます。得られたモデルの切片と傾きは、下記のintercept_属性とcoef_属性を参照することで確認できます。
print(lin_reg.intercept_, lin_reg.coef_)
# [2.57029274] [[3.4524941]]訓練データ・テストデータに対する正解率は、score属性を参照することで確認できます。
print(lin_reg.score(X_train, y_train))
print(lin_reg.score(X_test, y_test))
# 0.8294566068413886
# 0.8586332218270305今回の例の場合は、訓練データとテストデータに対するスコアは非常に近いため、過剰適合ではないことを意味します。このような1次元データセットの場合には、モデルは非常に単純なので過剰適合になる危険性は低いです。
また、データ分布に対して得られたモデル式をプロットすることで、データにどれだけ適合しているかを定性的に確認することができます。
plot_x = np.array([[0], [1]])
plot_y = lin_reg.intercept_ + lin_reg.coef_ * plot_x
plt.scatter(X, y)
plt.plot(plot_x, plot_y, color='red', ls='--')
plt.xlabel("X")
plt.ylabel("y")
plt.show()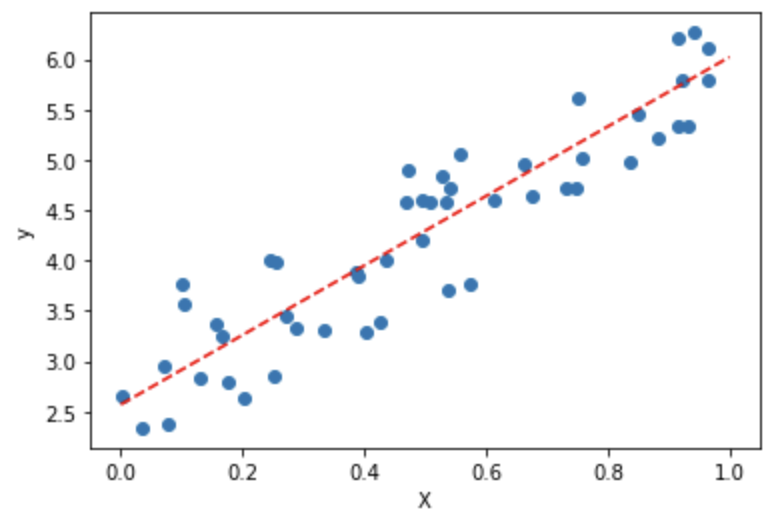
高次元データセットの予測
高次元のデータセットに対する線形回帰の予測は、過剰適合の可能性が高くなります。boston_housingの特徴量が104個に拡張されたデータセットを用いて、挙動を確認します。
import mglearn
X, y = mglearn.datasets.load_extended_boston()
print(X.shape)
print(y.shape)
# (506, 104)
# (506,)from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
lin_reg = LinearRegression().fit(X_train, y_train)
print("train score = ", lin_reg.score(X_train, y_train))
print("test score = ", lin_reg.score(X_test, y_test))
# train score = 0.9520519609032729
# test score = 0.6074721959666204訓練データのスコアは非常に高いのに対し、テストデータセットに対するスコアは大幅に下がっていることが確認できます。これは、訓練データに対して過剰適合が起こっていることを示しています。このような特徴量が多い場合の線形回帰には、単純な線形回帰ではなく別の手法が必要となります。
続きは、後編にて記述します。