
概要
本投稿では、Pythonを用いた機械学習の導入として、非常に有名なアイリス(アヤメ科の花)の種類の分類を行います。前提として、アイリスについて、花弁の長さと幅、ガクの長さと幅の測定結果と、setosa, versicolor, virginicaの3種類の分類結果を持っているものとします。
この機械学習モデルの目標は、新しく発見したアイリスの種類を、花弁の長さと幅、ガクの長さと幅の値から予測することです。このような問題は、クラス分類(Classification)問題の一例となります。
データの読み込み
ここで用いるアイリスのデータセットは、scikit-learnのdatasetに含まれており、下記の手順でロードします。
from sklearn.datasets import load_iris
iris_dataset = load_iris()データの確認
keys
読み込んだデータのKeyを確認することが可能です。
print(iris_dataset.keys())
# dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename'])DESCR
KeyのDESCRはデータセットの説明(description)です。データセットの概要を確認できます。この場合は、データ数や特徴量、分類したいクラス名、特徴量の最大値や最小値などを把握できます。
print(iris_dataset['DESCR'][:1000])
'''
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
'''target_names
target_namesには、予測したいアイリスの種類が格納されています。
iris_dataset['target_names']
# array(['setosa', 'versicolor', 'virginica'], dtype='<U10')fearute_names
feature_namesには、ガクの長さや幅など、特徴量の説明が格納されています。
iris_dataset['feature_names']
# ['sepal length (cm)', # ガクの長さ
# 'sepal width (cm)', # ガクの幅
# 'petal length (cm)', # 花弁の長さ
# 'petal width (cm)'] # 花弁の幅data
データはdataに格納されており、4つの特徴量の値がnumpy.ndarrayとして格納されています。配列のshapeを確認してみると、150個のアイリスの測定結果が格納されていることが分かります。。下のコードでは、dataの先頭5行の中身を確認しています。
type(iris_dataset['data'])
# numpy.ndarray
iris_dataset['data'].shape
# (150, 4)
iris_dataset['data'][:5]
# array([[5.1, 3.5, 1.4, 0.2],
# [4.9, 3. , 1.4, 0.2],
# [4.7, 3.2, 1.3, 0.2],
# [4.6, 3.1, 1.5, 0.2],
# [5. , 3.6, 1.4, 0.2]])target
targetには、測定した150個のアイリスの種類の正解ラベルが格納されています。
iris_dataset['target']
'''
#array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
'''target_names
targetの0, 1, 2の値は、それぞれ花の種類を表しています。
iris_dataset['target_names']
# array(['setosa', 'versicolor', 'virginica'], dtype='<U10')機械学習モデルの作成
訓練データとテストデータ
機械学習では、既に持っているデータを全てモデル構築に使用して、その精度を評価することはできません。これは、作成した機械学習のモデルが手持ちのデータの正解を覚えただけで、まだ見たことのない新しいデータに対しては、汎化出来ているか分からないからです。
そこで、モデルの性能を評価するためには、モデルにとって新しいデータを使用する必要があります。そのためには、手持ちのデータセットを訓練データとテストデータの2つに分けることが一般的です。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state = 0)train_test_split関数では、引数としたデータを一度シャッフルし、train:75% test:25%にデータ数を分割します。shape属性をそれぞれ参照することで、分割出来ていることを確認できます。また、random_stateパラメータを0に固定することで、train_test_split関数を何度呼び出しても出力が固定され、同じ結果を得ることができます。
print(X_train.shape)
print(y_train.shape)
# (112, 4)
# (112,)
print(X_test.shape)
print(y_test.shape)
# (38, 4)
# (38,)ペアプロットの作成
データを観察するために、特徴量の組み合わせをプロットします。まずは訓練データからpandas.DataFrameを作成し、’species’列を追加した後、ラベル名を花の種類に変更して、Pythonのグラフ描画ライブラリであるseabornを使用して、ペアプロットを描画しています。
import seaborn as sns
df = pd.DataFrame(X_train, columns = iris_dataset.feature_names)
df['species'] = y_train
df.loc[df['species'] == 0, 'species'] = 'setosa'
df.loc[df['species'] == 1, 'species'] = 'versicolor'
df.loc[df['species'] == 2, 'species'] = 'virginica'
df.head()
import seaborn as sns
pg = sns.pairplot(df, hue = 'species', palette = 'dark', plot_kws = {'alpha':0.8})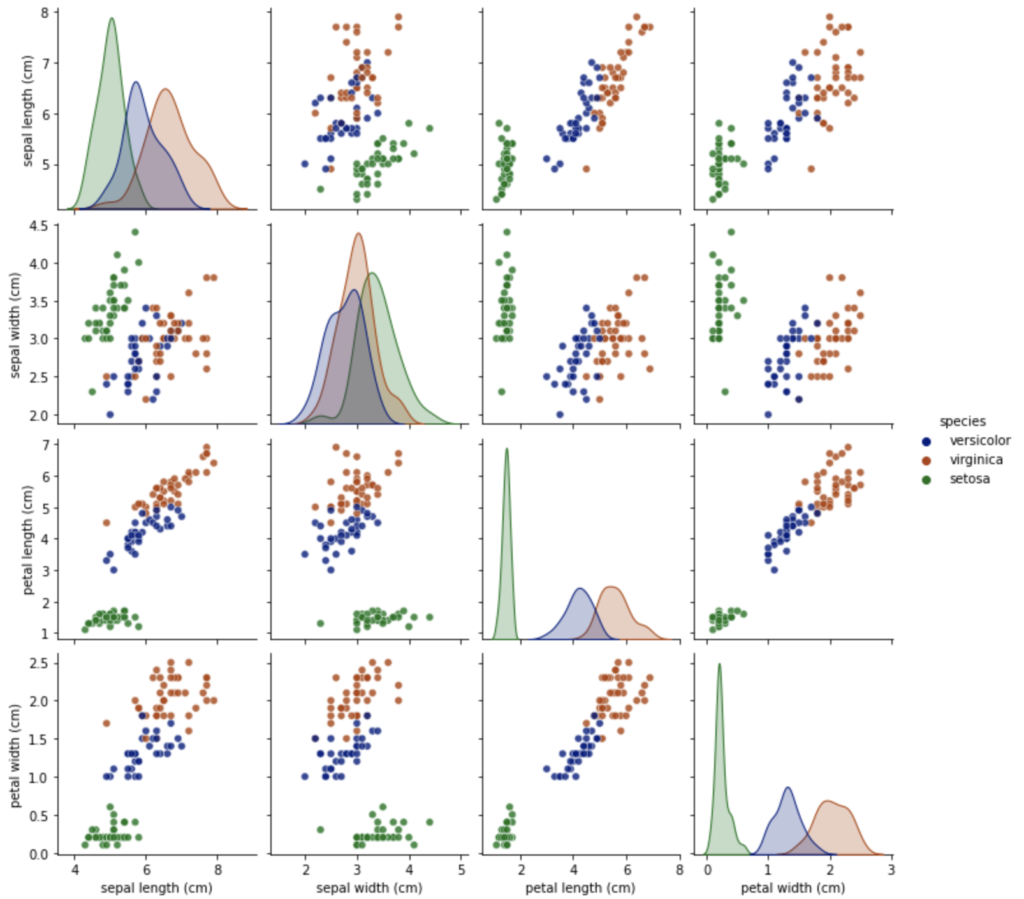
グラフから、4つの特徴量によって、花の種類は比較的分離していることが確認できます。
k-最近傍法
今回は、とても理解しやすいモデルであるk-最近傍法(k-Nearest Neighbors)によるクラス分類を使用します。k-最近傍法では、予測したいデータの点に対して、最も近い訓練データの点を探すことで、ラベルを判定します。
まずは、以下の手順でkNeighborsClassifierオブジェクトを生成します。引数n_neighborsに、近傍点の数を指定します。
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 3)訓練データからモデルを構築するには、作成したknnオブジェクトのfitメソッドを呼び出すだけで良いです。引数には、訓練データのX_trainと、そのラベルであるy_trainを指定します。
knn.fit(X_train, y_train)
# KNeighborsClassifier(n_neighbors=3)テストデータ(X_test)の花の種類を予測するには、knnオブジェクトのpredictメソッドを使用します。この結果を表示させると、0, 1, 2の花の種類が得られていることを確認できます。
y_pred = knn.predict(X_test)
print(y_pred)
#[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0 2]作成したモデルの精度を評価するためには、scoreメソッドを用います。今回作成したモデルでは、テストデータの正解ラベル(y_test)に対して、約97%の精度で予測が出来ていることを確認できました。
knn.score(X_test, y_test)
# 0.9736842105263158